
- 2025/3/18 18:01:05
- 类型:转载
- 来源:
- 网站编辑:阿卡
DeepSeek横空出世,一下子让更多的小伙伴有机会接触到高规格的人工智能助手,但也体验到了无数次“服务器繁忙,请稍后再试”的无奈等待。既然现在AI PC概念这么火热,那么有没有一种可能,在轻薄型笔记本上就可以部署DeepSeek,告别服务器繁忙的烦恼?还别说,包括DeepSeek在内的诸多大模型开源的特性足以让其在AI PC上运行,特别是蒸馏后的14B乃至32B大模型,在离线状态畅快玩转人工智能助手也没有压力。
现在不妨让我们以采用酷睿Ultra 200H(Arrow Lake-H)的轻薄型笔记本为例,仅凭一台轻薄本,是如何轻松完成DeepSeek本地部署的。


轻松配置DeepSeek
本地大模型部署,少不了先提到Ollama。Ollama作为开源的轻量级架构,可以在AI PC上轻松地构建、运行和管理大语言模型(LLM)。由于Ollama允许完全本地部署,无需依赖外部服务器或者云端,因此在数据保护上更具有隐私性和安全性。
而如果要Ollama流畅地在轻薄型笔记本上运行,IPEX-LLM是一个重要的途径之一。IPEX-LLM完整称呼是Intel LLM Library for PyTorch,顾名思义,是英特尔开发的一个开源的大语言模型(LLM)加速库,旨在优化英特尔CPU、GPU、NPU上的LLM推理和微调性能。换而言之,使用英特尔酷睿Ultra平台的PC会更占据优势。
这时候,再通过IPEX-LLM Ollama加载DeepSeek,
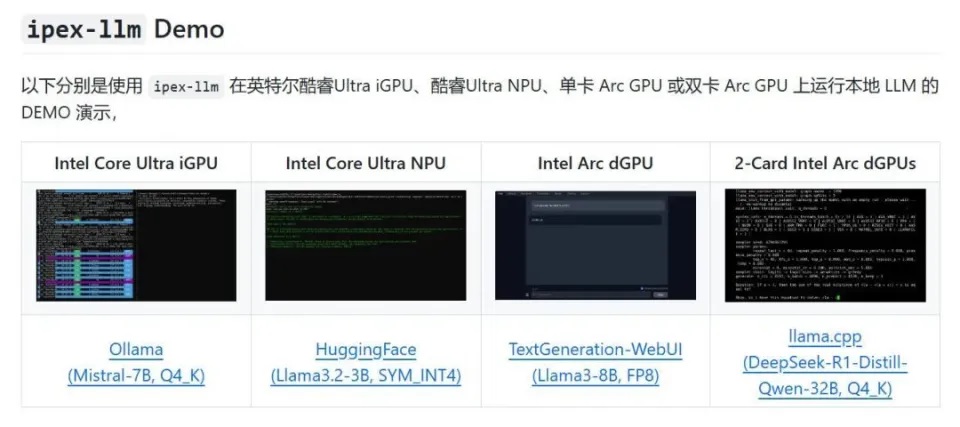
安装IPEX-LLM Ollama的方式非常简单,安装步骤只有三步,下载解压,启动Ollama服务,启动Ollama,大功告成。
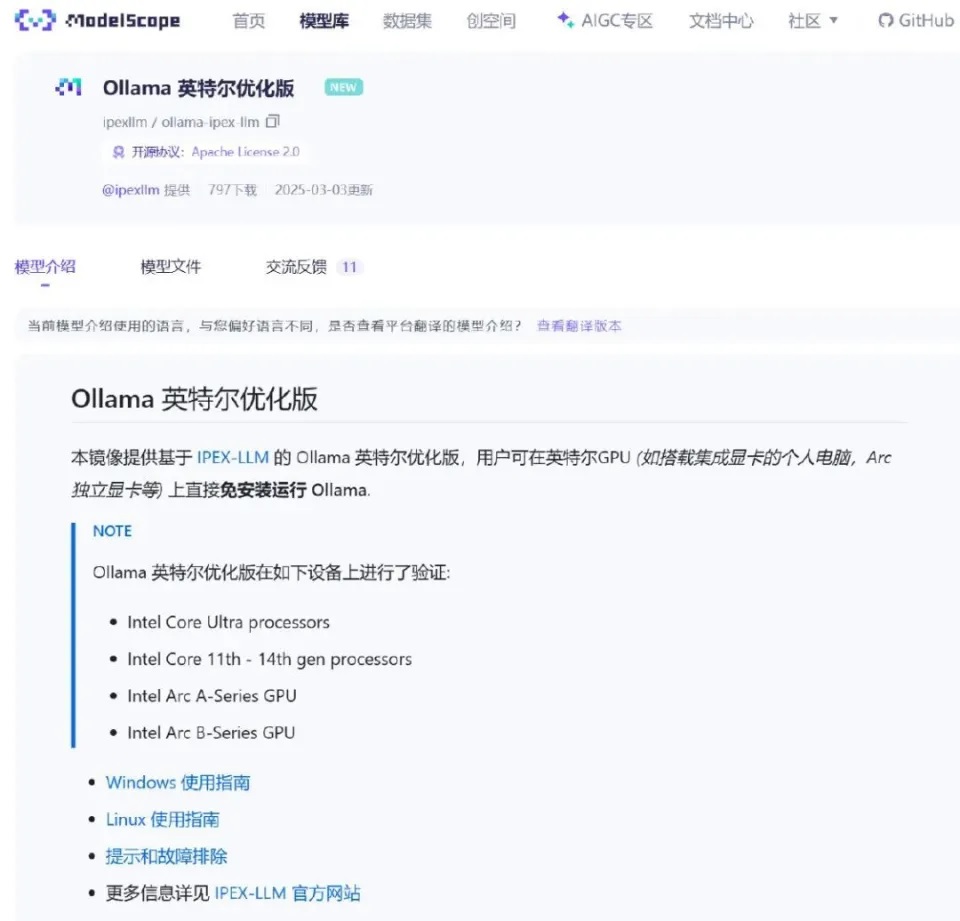
在魔搭社区ipexllm/ollama-ipex-llm就能看到专门的IPEX-LLM Ollama安装页面,这套基于IPEX-LLM的Ollama英特尔优化版已经针对11代到14代酷睿,酷睿Ultra系列,以及英特尔Arc A系列和B系列GPU优化。
因此在正式安装之前,笔者建议前往英特尔官网更新一下对应的驱动,比如酷睿Ultra 200H系列的iGPU,或者刚发布没多久的英特尔Arc B580,都需要最新驱动的支持。
言归正传。按照教程提示,将下载好后的Ollama解压到一个文件夹中,运行文件夹中的start-ollama.bat启动Ollama Serve,弹出的窗口不要关闭,通过cmd命令提示符窗口在解压缩的文件夹中运行Ollama即可。执行命令如下:
.\ollama run deepseek-r1:7b
这时候就会看到Ollama开始下载对应的DeepSeek模型,完成后,即可进入对话模式。
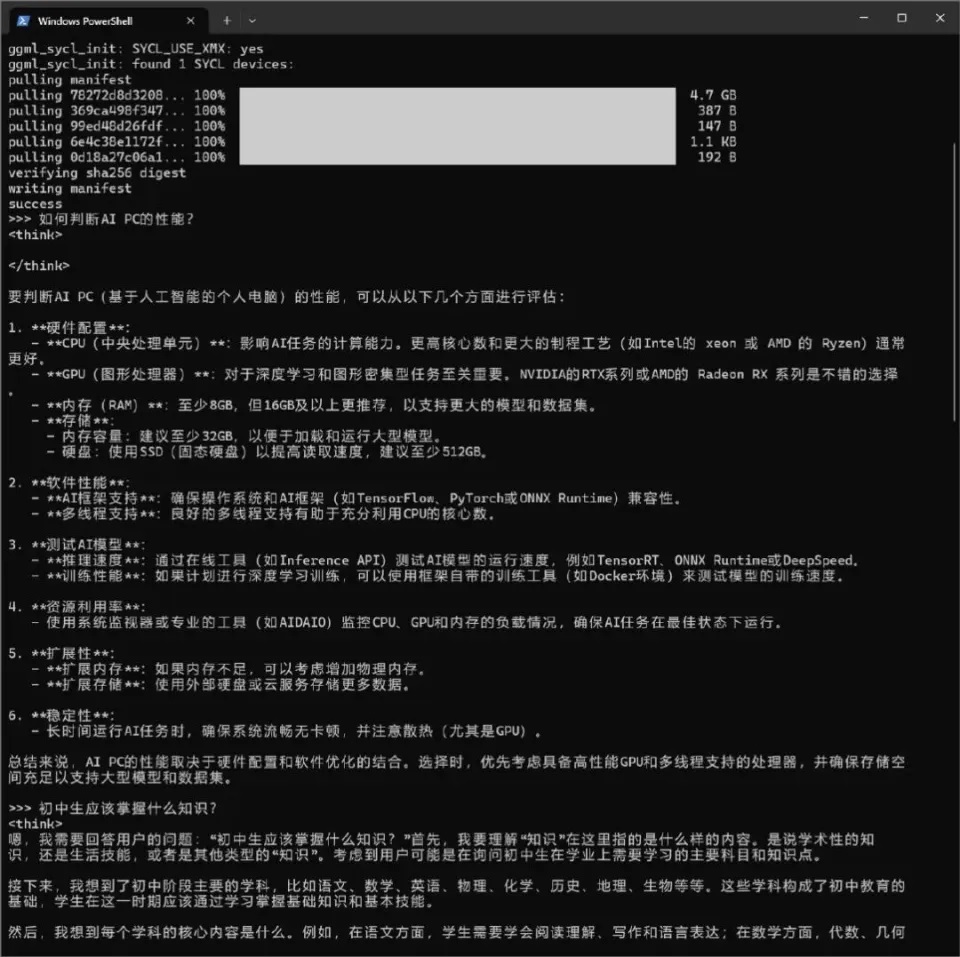
纯文字界面当然还差点意思,后续我们还可以通过ChatBox AI客户端,或者Edge浏览器插件,安装之后,客户端或者插件就会自动检测到之前安装的Ollama Serve,不需要更多的设置,就能获得更直观的交流界面,对话的方式也能帮助你获得更多与DeepSeek交流的灵感。

一步到位的Flowy
如果你觉得前面通过Ollama-IPEX-LLM三步走的方式仍然麻烦,这里还有一招更厉害的,即通过Flowy AIPC一步到位获得DeepSeek。这里只需要进入Flowy AIPC官网,下载安装程序,登陆,就可以一气呵成获得一套完整的人工智能对话界面。
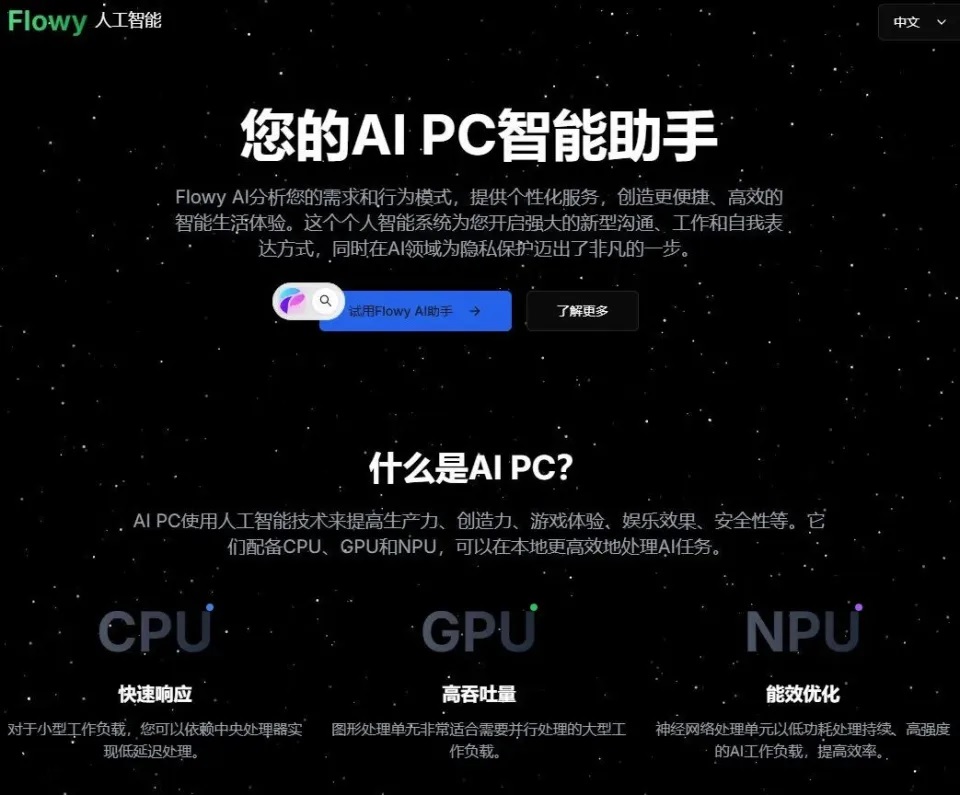
最新版的Flowy已经集成DeepSeek-V3、DeepSeek-R1、GLM-4-Flash、豆包模型。
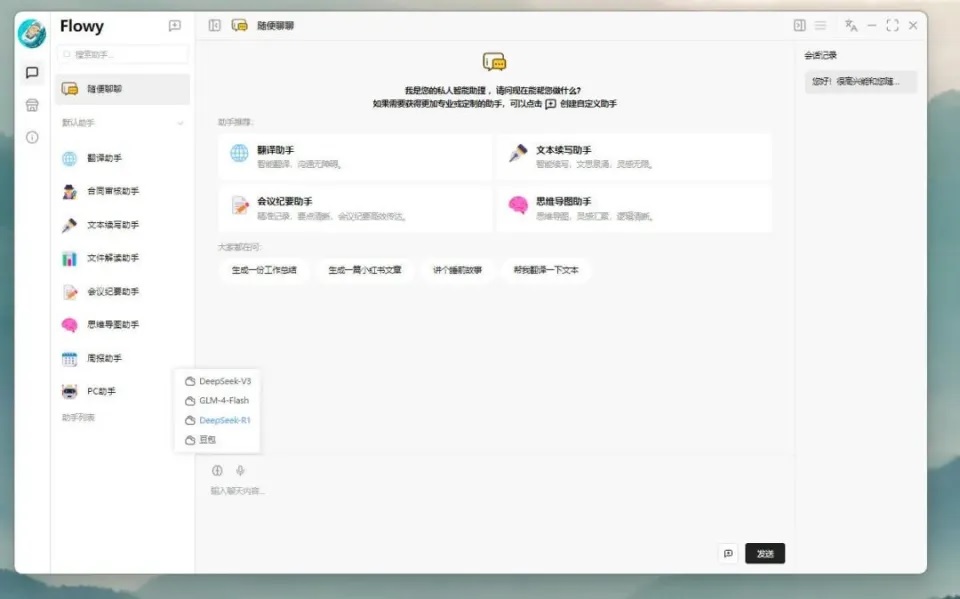
在模型市场本地模型中,你会发现Flowy已经帮你全部一口气部署好了。


性能如何?
Arrow Lake-H酷睿Ultra 200H系列则是定位主流标压笔记本,使用的Lion Cove P-Core和Skymont E-Core,相对上一代Meteor Lake-H在单线程和多线程性能上提升15%,并配备了Xe iGPU,除了最入门的版本之外,剩下的型号均配备Xe-LPG核显。由于酷睿Ultra 200H内置了11 TOPS的NPU,配合iGPU的77 TOPS和CPU的11 TOPS,可以达到99 TOPS的AI性能。
其中旗舰版本的酷睿Ultra 9 258H,拥有6个P-Core,8个E-Core和2个LP E-Core,总共拥有16个线程,得益于架构和IPC升级,在相同能耗的前提下性能是有所提升,同时也能让轻薄型笔记本在获得足够性能的同时,续航变得更长。在实际使用中,酷睿Ultra 200H的轻薄本续航明显优于酷睿Ultra 100H。

回到主题。得益于酷睿Ultra 200H对DDR5-6400和LPDDR5x-8400内存的支持,酷睿Ultra 200H轻薄本不仅默认使用的内存频率高,容量也动辄32GB,分给Xe-LPG核显调用的内存也更多,用来运行DeepSeek-R1:8B模型已经很轻松。
这里以酷睿Ultra 7 255H核显Arc 140T为例,通过DeepSeek-R1:8B模型描述“什么是AI PC”。这时候核显计算利用率达到100%,生成速度大概在15 tokens/s到20 tokens/s之间,在体感上已经与我们打字对话的速度上差不多了。
同样,如果运行Moonlight-16B-A3B模型进行数学公式计算或者诗词生成,生成速度也可以做到42 token/s上下,比两周前的19 token/s有了跨越式的进步,由此可见酷睿Ultra 200H运行大模型的潜力。

写在最后:一步到位的AI体验
从体验来看,采用酷睿Ultra 200H的轻薄型笔记本已经能够很好的离线运行DeepSeek-R1:8B模型,比如飞机上,信号不好高铁路段,笔记本离线就能充当起不错的助手作用。原本需要联网或者高性能台式机上才能实现的AI生成工作,现在一台基于Arrow Lake-H的酷睿Ultra 200H轻薄本就能完成。
原本在线服务总是繁忙的DeepSeek-R1,现在仅通过简单的三步配置,就能在酷睿Ultra 200H轻薄本上完成部署。英特尔早已搭建好的Ollama+IPEX-LLM环境,在这个应用场景中立了大功。

这是一套由英特尔搭建,基于酷睿Ultra系列生态环境,通过诸如Flowy AI PC助手这样的便捷应用,可以一键部署7B到14B的DeepSeek本地大模型,并且功能非常丰富。现在酷睿Ultra 200H轻薄本配合国补价格已经可以来到5000元价位档,这让原本硬件和使用技巧都要求颇高的大模型应用,现在变得唾手可得。如果你想在近期获得一个高智商且能离线运行的AI助手,购置一款酷睿Ultra 200H轻薄本就是一个很不错的解决方案。
Copyright © 2006-2021 电脑报官方网站 版权所有 渝ICP备10009040号-12